- Частина 1. Підбір семантики
- Сервіси для кластеризації запитів
- Альтернативні способи збору семантики
- Частина 2. Кластеризація запитів
- Частина 3. Кластерізатор від SEOquick
- Крок 1. Угруповання за тематикою
- Крок 2. Оцінка сумісності слів на 1 сторінці по топу видачі
- висновки
- Частина 3. Автоматична кластеризация запитів
- Кластеризація по топу / url
- Тематична (семантична) кластеризація
- Частина 3. Фінальна кластеризация запитів
- Крок 1. Перегляд кластерів.
- Крок 2. «Вага» кластера
- Крок 3. Підбір сторінок
- Частина 4. Заключна
Семантичне ядро (СЯ) сайту - ключовий елемент при його просуванні. Більш того, від якості СЯ багато в чому залежить і ефективність роботи PPC-кампаній (Pay-per-Click - показ рекламних оголошень в мережах Google AdWords або Яндекс.Директ). Тому складання семантичного ядра і кластеризація запитів - перше, що потрібно зробити при роботі над просуванням сайту в пошуку або створенні рекламних оголошень .

Але просто зібрані ключові слова складно використовувати в роботі, адже їх необхідно впорядкувати. Тому після збору СЯ йде кластеризация запитів - їх поділ на групи (кластери), відповідно до особливостей і властивостями.
В рамках теми, розглянемо процес в дії, а також можливі способи автоматизації. Однак торкнемося лише ключові аспекти та сервіси, оскільки кластеризация занадто багатогранна і для її опису доведеться випустити пару томів.
Частина 1. Підбір семантики
Первинний SEO аналіз сайту досить показовий, щоб визначитися із загальною тематикою ключових слів. Чи не доведеться залучати якихось фахівців або звертатися до сервісів, щоб визначитися з тематикою. На цьому етапі все просто. Адже «про що пишемо, ті запити і використовуємо».

Складнощі починаються потім: далеко не завжди зрозуміло, як саме думає користувач, якому виявиться корисний ваш сайт. Якщо детально розбирати кожен запит, то можна зустріти явище, яке називається «потоком свідомості».
Сервіси для кластеризації запитів
Наприклад, людину цікавить просування спільноти в Facebook. Але шукати інформацію про це він може і за запитом «Як просунутися в мордокнигою» (мордокнигою - сленгове назва соцмережі Facebook). І це теж доведеться врахувати в роботі над семантикою.
Рятує тут те, що складання семантичного ядра для сайту ведеться за допомогою спеціалізованих сервісів.
- Wordstat - підбір пошукових запитів Яндекса. Частково спрощує кластеризацию, оскільки в таблиці присутні всі слова з початкового запиту з додатковими формулюваннями.
- Keyword Planner - практично аналогічний сервіс від Google.
- тренди Google - ще один помічник, який покаже запити, що набирають популярність.
Деякі блогери включають в список Google Correlate, що відображає інші варіанти запитів, засновані на поведінкових даних користувачів пошукової системи. Однак в російськомовному сегменті мережі, «відв'язати» від США географічно, цей сервіс не придатний, на жаль.
Але популярність слова «мордокнигою», стосовно Facebook, ці сервіси не відобразять. Тому вибірку ключів, за якими вестиметься кластеризация запитів, варто провести і по інших сервісів. Вибір досить великий:
- Готові бази. Переваги - все зробили за вас. Недоліки - не найвища достовірність, адже не враховуються тренди і поточна популярність ключів. З популярних в .ru зоні - Мутаген, UP Base.
- Спеціалізовані сервіси дадуть уявлення про те, за якими запитами просувається сайт, причому деякі покажуть СЯ конкурентів. Найбільш популярні SEMRush, Key Collector, Alexa, Ahrefs.
Альтернативні способи збору семантики
Розглядати всі сервіси для збору семантики не має сенсу. Їх занадто багато, вони відрізняються механізмами роботи, додатковими параметрами. До того ж, всі вони різного ступеня платності. Якісних оглядів в мережі достатньо, тому підібрати оптимальний за співвідношенням ціни, якості та зручності не складе труднощів.
Але який спосіб збору семантики віддати перевагу? Порівняємо безвідносно конкретних сервісів, а за загальними ознаками:
 Для пошуку синонімів можна скористатися 3 варіантами:
Для пошуку синонімів можна скористатися 3 варіантами:
- Ручний збір за підказками пошукової системи. Наприклад, Google останнім часом часто показує схожі запити в форматі «також шукають». Але не обов'язково, що вдасться почерпнути якісь унікальні слова.
- Аналіз СЯ конкурентів. Але тут слід розуміти, що знайдеться далеко не вичерпний список, і охоплення може виявитися не настільки великим, яким він міг бути.
- Спеціалізовані сервіси, наприклад, Serpstat. Система «вміє» працювати зі схожими фразами, і кількість синонімічних запитів досить велика. Але знову ж таки, кластеризація запитів відбувається не всеохоплююче.
Варто спробувати все 3 способи, щоб отримати якомога більший радіус дії синонімів і тематично схожих слів. Чим ширше охоплення, тим більший цільовий трафік вдасться залучити.
Але при аналізі конкурентів потрібно звернути увагу на структуру їхніх сайтів, пропонований асортимент і додаткові послуги. Інакше в необроблену базу запитів потрапить «сміття», що не відповідає змісту сайту, які буде просуватися.
Наприклад, передбачається займатися тільки продажем садоогородних товарів, з послуг - доставка. У конкурентів розширено товарний асортимент за рахунок будматеріалів, малих архітектурних форм. З додаткових послуг крім доставки - ландшафтний дизайн, консультації агронома, вивіз будівельного і рослинного сміття, спіл дерев і обрізка кущів. Отже, все, що не відноситься до вже вашому бізнесу - непотрібне сміття, парсити який не має сенсу.
Так чи інакше, але після закінчення підбору ключових слів з'являється великий список, який можна імпортувати в форматі електронної таблиці для подальшої обробки. Здається, складання семантичного ядра завершено. А що робити з усім цим "багатством"?
Відразу приступати до створення контенту? Тоді як визначитися, які ключі будуть на кожній сторінці? А що, якщо підсумком роботи над СЯ стає 1000+ ключових слів? Така кількість сторінок для невеликого сайту не потрібно, та й не всі запити "однаково корисні". Деякі хоч і пов'язані тематично, але сенсу від їх використання не буде ніякого.
Наприклад, складається семантика для сайту пасіки. І тут доречними виявляться і просто "мед" - інформаційний запит і «купити мед» - комерційний запит. А ось «лікування подагри медом» вже не має відношення до тематики сайту, хоча на перший погляд здається, що використовувати цей запит доцільно.
Ось для розподілу запитів і потрібна кластеризація ключових слів . Тобто, потрібно розподілити всі слова по «тематичними групами» - кластерам, відповідно до яких визначити кількість сторінок і створити унікальний контент для просування в пошукових системах або PPC-реклами.
Частина 2. Кластеризація запитів
Відразу обмовлюся, що не розглядають кластеризацию в розрізі «soft» і «hard». Здебільшого для комерційних сайтів використовується саме hard кластеризація. Варіант м'якою класифікації використовується рідко і, на мою думку, для низькочастотних запитів (тобто тих ключів, за якими конкуренція низька).
Також хочу зазначити: якщо сайт складається з 3-5 сторінок, а для просування відбирається менше 10 ключів, то особливої потреби в кластеризації СЯ не виникає.
Інша річ, коли відібрано 1000+ запитів. В цьому випадку потрібно виконати 3 кроки
- Згрупувати ключі по тематиці.
- Розподілити ключі по групах, в залежності від їх знанченія.
- Оцінити сумісність ключових слів для їх використання в межах 1 сторінки сайту
Частина 3. Кластерізатор від SEOquick
Кластеризація запитів від SEOquick дозволяє здійснювати морфологічний пошук автоматично. Досвідчені фахівці знають, що це доводиться робити вручну, або при великих фінансових витратах. Ось кілька аргументів на користь використання інструменту:
- Швидка робота (якщо раніше вам потрібно 1 - 2 дні, щоб створити повноцінний список, тепер треба 5 хвилин).
- Абсолютно безкоштовний, хоча аналогічні програми коштують дорого (наприклад, за 3000 слів доведеться віддати 20 $).
Крок 1. Угруповання за тематикою
Ключові слова розподіляються за групами, відповідно до структури сайту. Припустимо, що необхідно просунути інтернет-магазин, присвячений садівництву і продажу насіння, добрив, інвентарю. Умовно відокремлюємо комерційні запити «купити», «ціна», «дешево» від інших.
Потім розподіляються слова по групах - «томати», «огірки», «інвентар», «добрива». Кількість груп визначає первинний SEO аналіз сайту, якщо ресурс вже існує. Якщо немає або є проблеми в структурі, групи доповнюються або створюються «з нуля».
Також варто визначитися з геозалежні і не очевидною комерцією. Що це? Для прикладу - єдине і множинне число. Звернемося до пошуковиків:
Баклажан для Яндекса - інформаційний запит, а баклажани вже комерційний. Те ж саме і в Google .
Крок 2. Оцінка сумісності слів на 1 сторінці по топу видачі
Далеко не всі слова «уживаються» разом на сторінці. Але самостійно виділити і визначити сумісність, особливо якщо немає досвіду, практично неможливо.
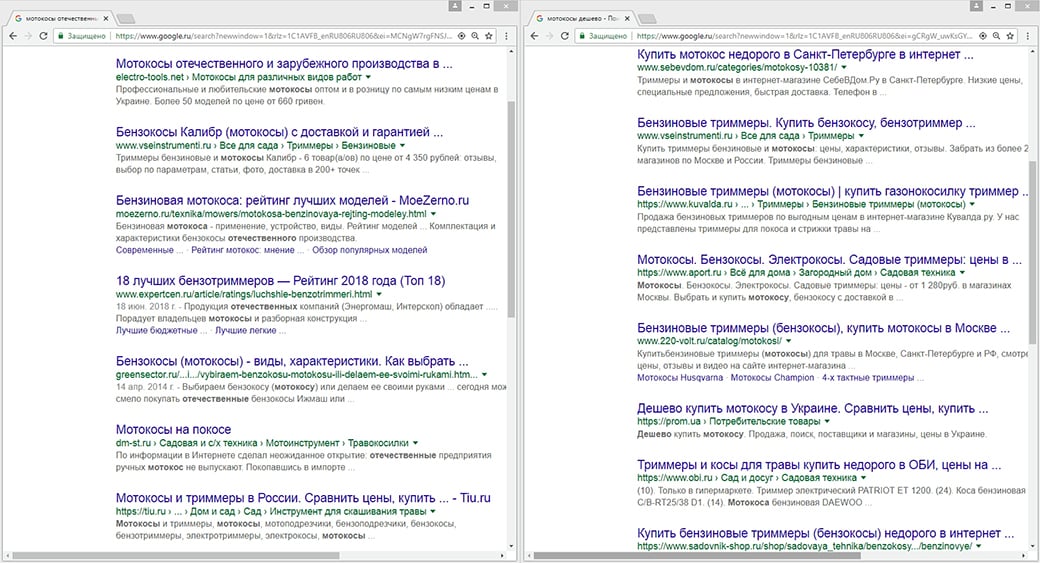
Уявімо ситуацію, що на 1 і 2 кроці помилок не скоєно і групи зібрані з ідентичною тематикою. Перейдемо до перевірки по URL. Для цього вбиваємо в пошук фразу «мотокоси купити москва», а потім «мотокоси москва». Збігається 4 url, отже, ці ключі можна використовувати на 1 сторінці.
Продовжимо далі: «мотокоси вітчизняні» і «мотокоси дешево» не мають збігів. Відповідно, варто рознести ці ключі на різні сторінки - разом вони не «уживуться».
висновки
Закономірна думка: маючи близько 100 запитів, кластеризувати їх вручну за тематикою і морфології ще реально. Але банальна перевірка по ТОП / url займе тижні, місяці, роки. Час буде витрачено даремно.
Але з першими кроками теж не все просто. Якщо в таблиці буде 1000+ запитів, то тільки лише на розподілі їх по групах і оцінці релевантності «зламаються очі» вже через 8-10 годин безперервної роботи. До того ж, людська пам'ять «коротка», і можливість пропустити якісь запити або створити зайві кластери тим вище, чим більше складною структурою володіє сайт.
Давайте порахуємо кількість сторінок для 1 невеликого сайту пасіки:
- Розділи: Головна сторінка + Про компанію + Доставка і оплата + Товари + Блог (огляди / новини / etc.).
- Для розділу Доставка і оплата - 2 сторінки (або 1 з великим кластером)
- Товари - кількість сторінок відповідає асортименту, але навіть якщо продається всього лише 5 сортів меду, вулики і бджоли, то кількість сторінок складе 10-15.
Вважаємо: В цілому більше 20 кластерів, для кожного з яких близько 2 запитів. 20х2 = 40. Обробка 40 запитів займе не менше дня. Ось тільки фактичний обсяг, який доведеться «перелопатити» варто сміливо множити на 10, якщо семантика збиралася автоматично.
Отже, доведеться автоматизувати цей процес.
Частина 3. Автоматична кластеризация запитів
На допомогу оптимізаторові створено чималу кількість сервісів автоматичної кластеризації. Їх суть - пропуск 1 і 2 кроків і обробка всього масиву запитів тільки за збігом url. Є й альтернативні методи поділу. Кластеризація ключових слів тут виконується тільки по кроку 2.
Хочу зауважити: тематичний поділ запитів знадобиться тільки при роботі вручну. У всіх інших випадках алгоритми кластеризації впораються самостійно. Але це не означає, що кінцевий результат не доведеться вивчати на предмет помилкового рознесення ключів по підгрупах.
Кластеризація по топу / url
Передбачається, що при такому підході враховується алгоритм ранжирування пошукової системи, отже, і поділ ключів на групи виявиться найбільш точним. Але очевидних мінусів тут предостатньо.
- Алгоритми ранжирування змінюються. Згадаймо доленосні апдейти у Google - Florida, Panda, Penguin, Pigeon. А адже ранжування адаптується видачу не під сайти, а під користувачів пошукової системи. А вона змінюється з часом. Через 1-2 місяці список сайтів за запитом виявиться зовсім іншим.
- Різні пошукові системи - різні результати. Порівняємо видачу за однаковим запитом у Google і Яндекс: за запитом «мотокоса» вона відрізняється досить сильно, знайшовся всього перетинається 1 url.
- Включення в групу неоднорідних слів, які складно використовувати при створенні контенту. Уявіть варіант, коли в кластер поміщається слова «насіння герман ф 1» і «корнішони 6 соток». Так, мова про огірки, а й ключі різної тематики (1 відноситься до насіння, 2 - до продукції певного бренду). Пов'язати їх між собою на картці товару не те щоб неможливо, але копірайтер доведеться попітніти.
До певних мінусів можна віднести відносну дорожнечу сервісу. Однак тут слід розуміти, що інструмент не завжди може бути безкоштовним. І кожен сам для себе вирішує, чи готовий він платити і чи варто послуга співвідношення ціни і якості.
Другий, не цілком очевидний недолік - необхідність доопрацювання семантики. І подвійно прикро, якщо кластеризация запитів була платною. Причому сервіси запитують чималі суми, від 150 USD і вище.
Особисто моє враження від кластеризації методом url / топа видачі - спроба зробити професійний інструмент не цілком розбираючись, як насправді працюють алгоритми ранжирування. І замість реальної роботи над контентом і семантикою фахівці пішли шляхом найменшого опору, покладаючись лише на примітивний перебір варіантів.
Опоненти ж стверджують, що подібний підхід - єдино правильний, оскільки гарантує потрапляння в ТОП. Сюди ж «приплітається» LSi (latent semantic indexing - приховане семантичне індексування), оскільки існує «притча» про якусь семантичної залежності між словами.
Насправді, і тут є свої нюанси:
- Якщо на сторінці зустрічаються 2 запити, то це означає, що не Яндекс або Google їх визнав найбільш релевантними, а що веб-майстер (SEO-специалист) конкретного сайту їх туди помістив.
- Семантична залежність існує, але у відриві від ранжирування. До того ж LSi - це більше кластеризация запитів по тематиці / морфології, але не по топу / url
- Видача адаптована під конкретного користувача, тоді як кластерізатори працюють у відриві від неї. Відповідно у кінцевого користувача «картинка» виявиться зовсім інший, ніж у сервісів під час роботи над семантикою
Тематична (семантична) кластеризація
Альтернативою сервісів поділу ключів по групах на основі ТОП / url є тематичні кластерізатори.
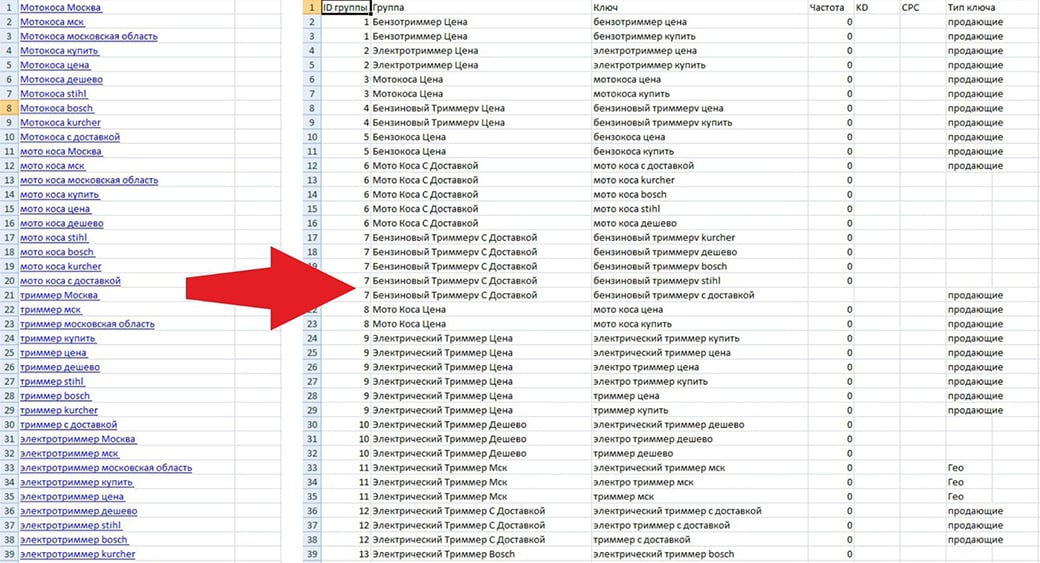
Тут правлять бал дещо інші принципи, які можна охарактеризувати наступним чином:
- Аналізується семантична залежність кожного із запитів. Чи не LSi в чистому вигляді, але щось близьке. Адже алгоритму потрібно не просто виявити головне слово в запиті, а й підібрати для нього пару / аналог, який має абсолютно ідентичне значення. Наприклад, «томати - помідори», «мотокоса - бензиновий тріммер». У той же час сервіс повинен вміти розділяти нерівні за змістом, але схожі по написанню ключі. «Цибулини тюльпанів - цибулини (в значенні цибуля ріпчаста)».
- Аналізується склад фрази за словами / поєднанню. Чи не семантична (смислова, синонімічна) залежність, а саме кількість однокореневих слів або цілих фраз з них. Наприклад «купити насіння герман ф1 - купити герман ф1».
- Аналіз геозалежні. Ділові пропозиції від геозалежні. Кластеризація ключових слів обов'язково включає в себе фактичний джерело запиту. Адже одна справа, коли інтернет-магазин працює по Москві, і інше - по Владивостоку. Зрозуміло, що для семантичного ядра московського магазину запит «мотокультиватор владивосток» абсолютно даремний, і його не повинно бути ні в одній з груп.
Недоліки є і у цього методу, однак вони не такі критичні, як у випадку з кластеризацией по ТОП / url.
Перш за все - синонімізація, яку не завжди коректно виконує алгоритм кластерізатора. Для програмного коду фрази «електротріммер - електрокоса», «насос СН90-В - насос СН 90» не завжди мають знак рівності, оскільки "комп'ютер" не володіє абстрактним мисленням і тому цілком може рознести їх по різних групах.
Другий аспект - внесення в одну групу несумісних запитів. Наприклад, тип техніки: «Погружной грязьовий насос - погружной свердловинний насос» відносяться до різних типів. Ще гірше йдуть справи з моделями техніки: «насос SP1 - насос SP3».
Третій аспект - користувачі не завжди повністю вказують місце розташування пошуку або пошукові системи неправильно визначають регіон, відповідно, автоматична кластеризация запитів не обов'язково врахує цільової регіон.
Візьмемо для прикладу Костромську область: Яндекс і Google вважають всі населені пункти області за м Кострому. Однак жителям Шарьі видача для обласного центру не принесе користі. Відстань близько 300 км зробить покупку насіння у подільському інтернет-магазині непривабливою.
Отже, результати роботи кластерізатора доведеться правити вручну, навіть якщо сервіс пропонує самостійно вказати нерозривні слова, регіональну приналежність і список синонімів. Але часу на це витратитися все одно менше, ніж, якщо намагатися все зробити самостійно.
Частина 3. Фінальна кластеризация запитів
Файл практично готовий, з нього прибраний зайвий сміття. Залишилося переглянути кластери, порахувати їх вага і рознести по категоріях.
Крок 1. Перегляд кластерів.
Деякі кластери після правок мають, по суті, однаковою ознакою, але різним набором ключів. Отже, все їх потрібно перевірити і видалити зайві, тобто ті, які не будуть взяті в роботу ні зараз, ні коли-небудь потім.
Крок 2. «Вага» кластера
Для кожного ключового слова встановлена частотність. За високочастотним запитам конкуренція більше, але і прибуток від них вище. SEO-фахівці застосовують різні підходи, але найчастіше намагаються використовувати на сторінці запити з різною частотністю - тільки ВЧ, тільки СЧ, тільки НЧ або їх поєднання.
На цьому кроці можна перегрупувати запити по кластерам, розподіливши їх у відповідності зі своєю звичкою. Наприклад, об'єднати ВЧ-кластери, або навпаки - розбавити їх НЧ або СЧ.
Крок 3. Підбір сторінок
Кластеризація запитів, виконана для вже існуючого сайту, потребують підбору сторінок для кожного зі створених кластерів. Можна піти двома шляхами:
- Перерозподілити ключі по сторінках відповідно до карти сайту.
- Розподілити кластери з перевіркою через пошуковик.
В останньому випадку в пошуковий рядок вбивається запит формату «Ваш сайт» + «Основний Запит Кластера» (у якого найвищу вагу) і береться сторінка, яка виявиться 1 в списку. Але тут може виникнути казус: загальний вміст сторінки і сенс ключа фактично не релевантні.
Частина 4. Заключна
Якщо все зробити правильно, то на виході вийде файл, в якому:
- всі ключові слова зібрані за групами (кластерам) і об'єднані за змістом;
- для кожного кластера прорахований вага, що визначає черговість робіт для копірайтера / контент-менеджера / адміністратора / програміста;
- підібрана цільова сторінка або розділ сайту, релевантний запитам.
Розглянута кластеризация запитів багато в чому спрощує просування сайту в ТОП. Але потрібно розуміти, що це - далеко не панацея, і без додаткових зусиль нічого не спрацює. Під отримане СЯ необхідно створити унікальний контент (тобто, дати завдання копірайтер і / або редактору / контент-менеджеру), організувати відповідну структуру.
Але який спосіб збору семантики віддати перевагу?А що робити з усім цим "багатством"?
Відразу приступати до створення контенту?
Тоді як визначитися, які ключі будуть на кожній сторінці?
А що, якщо підсумком роботи над СЯ стає 1000+ ключових слів?
Що це?